La precisión en la simulación del diseño mejora el
desarrollo del producto.
¿Cómo la precisión de la simulación beneficia al desarrollo de productos?
Lograr desarrollar productos con éxito exige innovación,
fiabilidad y rapidez. Como ingeniero de diseño, no solo debe satisfacer los
requisitos de forma, ajuste y funcionalidad, sino también crear diseños de
productos únicos, fiables y que se puedan fabricar con rapidez y a un bajo
coste. A fin de lograr estos objetivos, necesita disponer de tanta información
y con la mayor antelación posible sobre el rendimiento del diseño en
condiciones de funcionamiento reales, sin tener que echar mano de costosas
pruebas de prototipos físicos o simulaciones subcontratadas que requieren una
gran inversión de tiempo. Con las soluciones integradas de SOLIDWORKS
Simulation también puede ejecutar precisas simulaciones de FEA directamente en
el software CAD SOLIDWORKS, lo que le proporciona acceso rápido a los
resultados del análisis estructural en las primeras fases del proceso, con
datos sobre los niveles de tensión, la forma deformada o la vida útil del
producto, entre otros.
Con esta información vital, puede tomar decisiones de diseño
críticas que la ayudarán a:
• Innovar en el desarrollo de productos
• Reducir la elaboración de prototipos
• Acelerar el tiempo de comercialización
• Optimizar el uso de
materiales
• Eliminar las imprecisiones del diseño
• Minimizar los problemas de rendimiento
• Reducir el número de reclamaciones y devoluciones relacionadas
con la garantía
• Incrementar la rentabilidad Con su intuitiva interfaz de
usuario, potentes solvers y amplias capacidades de análisis, SOLIDWORKS
Simulation le proporciona una solución de diseño integrada que no solo es más
rápida y fácil de usar, sino también tan precisa como cualquier otro paquete de
simulación. En este documento se examinará la precisión del análisis y cómo la
exclusiva combinación de precisión, facilidad de uso y potencia del software
SOLIDWORKS Simulation puede contribuir a los esfuerzos de desarrollo de su producto.
¿Con qué grado de precisión simula fea La realidad? En general, los sistemas
FEA utilizan el método de elementos finitos, una técnica de desratización
numérica para aproximar soluciones a los problemas de contorno para las ecuaciones
diferenciales que rigen tanto la física como la ingeniería. El modelo se
representa como una desratización de la geometría, mallando la geometría
con elementos. Dado que las soluciones de FEA, independientemente del paquete,
están basadas en el método de elementos finitos, sus resultados serán siempre
una aproximación lo suficientemente próxima como para proporcionar la precisión
requerida para tomar decisiones diseño importantes, pero nunca una
representación perfecta de la realidad, ya que incluyen un error de
discretización. Los solvers de FEA utilizan algoritmos computacionales a fin de
generar ecuaciones diferenciales para cada componente de geometría del diseño,
restricciones, propiedades del material y cargas. A continuación, convierten
las ecuaciones diferenciales en una matriz de ecuaciones para cada elemento, a
fin de generar una matriz global de ecuaciones para el modelo. Por lo general
se resuelve utilizando solvers Direct Sparse o iterativos: los solvers Direct
Sparse utilizan el método de eliminación Gausiano para resolver la matriz
global de ecuaciones; los solvers iterativos, por su parte, emplean el
método de descomposición de dominios. Los fundamentos matemáticos de FEA
implican que los ingenieros deben aplicar cargas y condiciones de contorno con
precisión para acercarse tanto como sea posible a la respuesta real. Dado que
FEA representa una aproximación muy precisa del rendimiento del diseño, simular
la realidad con tanta exactitud como sea posible exige la correcta preparación
del problema de análisis. La pregunta acerca del grado de precisión con que FEA
simula la realidad debería ser: ¿cuánta precisión necesitamos en realidad? En
la mayoría de los casos, un porcentaje de ±5 proporcionará la información
necesaria para tomar las decisiones de diseño correcto.
www.solidworks.es
4.4.2. Cálculo del número mínimo de
observaciones necesarias
El tamaño de la muestra o cálculo de número de observaciones es un proceso vital en la etapa de cronometraje, dado que de este depende en gran medida el nivel de confianza del estudio de tiempos. Este proceso tiene como objetivo determinar el valor del promedio representativo para cada elemento.
Los métodos más utilizados para determinar el número de observaciones son:
Método Estadístico
Método Tradicional
Método estadístico
El método estadístico requiere que se efectúen cierto número de observaciones preliminares (n’), para luego poder aplicar la siguiente fórmula:
NIVEL DE CONFIANZA DEL 95,45% Y UN MÁRGEN DE ERROR DE ± 5%
Siendo:
n = Tamaño de la muestra que deseamos calcular (número de observaciones) n’ = Número de observaciones del estudio preliminar Σ = Suma de los valores x = Valor de las observaciones. 40 = Constante para un nivel de confianza de 94,45%
Ejemplo:
Se
realizan 5 observaciones preliminares, los valores de los respectivos
tiempos transcurridos en centésimas de minuto son: 8, 7, 8, 8, 7. Ahora
pasaremos a calcular los cuadrados que nos pide la fórmula:
n’ = 5
Sustituyendo estos valores en la fórmula anterior tendremos el valor de n:
Dado
que el número de observaciones preliminares (5) es inferior al
requerido (7), debe aumentarse el tamaño de las observaciones
preliminares, luego recalcular n. Puede ser que en recálculo se determine que la cantidad de 7 observaciones sean suficientes.
Método tradicional
Este método consiste en seguir el siguiente procedimiento sistemático:
1.
Realizar una muestra tomando 10 lecturas sí los ciclos son <= 2
minutos y 5 lecturas sí los ciclos son > 2 minutos, esto debido a que
hay más confiabilidad en tiempos más grandes, que en tiempos muy
pequeños donde la probabilidad de error puede aumentar.
2. Calcular el rango o intervalo de los tiempos de ciclo, es decir, restar del tiempo mayor el tiempo menor de la muestra:
R (Rango) = Xmax – Xmin
3. Calcular la media aritmética o promedio:
Siendo: Σx = Sumatoria de los tiempos de muestra n = Número de ciclos tomados
4. Hallar el cociente entre rango y la media:
5. Buscar
ese cociente en la siguiente tabla, en la columna (R/X), se ubica el
valor correspondiente al número de muestras realizadas (5 o 10) y ahí se
encuentra el número de observaciones a realizar para obtener un nivel
de confianza del 95% y un nivel de precisión de ± 5%.
Ejemplo
Tomando
como base los tiempos contemplados en el ejemplo del método
estadístico, abordaremos el cálculo del número de observaciones según el
método tradicional.
En primer lugar como el ciclo es inferior a
los 2 minutos, se realizan 5 muestras adicionales (6, 8, 8, 7, 8) para
cumplir con las 10 muestras para ciclos <= 2 minutos. Las
observaciones son las siguientes:
Se calcula el rango:
R (Rango) = 8 – 6 = 2
Ahora se calcula la media aritmética:
Ahora calculamos el cociente entre el rango y la media:
Ahora buscamos ese cociente en la tabla y buscamos su intersección con la columna de 10 observaciones:
Tenemos entonces que el número de observaciones a realizar para tener un nivel de
confianza del 95% según el método tradicional es: 11
Al adicionar los 5 tiempos y utilizar el método estadístico tenemos un número de observaciones igual a: 12.8 aproximadamente 13.
Por
lo cual podemos concluir que ambos métodos arrojan resultados muy
parecidos y que la elección del método se deja a criterio del
especialista.
Un intervalo de confianza es una técnica de estimación utilizada en inferencia estadística que permite acotar un par o varios pares de valores, dentro de los cuales se encontrará la estimación puntual buscada (con una determinada probabilidad).
Un intervalo de confianza nos va a permitir calcular dos valores
alrededor de una media muestral (uno superior y otro inferior). Estos
valores van a acotar un rango dentro del cual, con una determinada
probabilidad, se va a localizar el parámetro poblacional.
Intervalo de confianza = media +- margen de error
Conocer el verdadero poblacional, por lo general, suele ser algo muy
complicado. Pensemos en una población de 4 millones de personas.
¿Podríamos saber el gasto medio en consumo por hogar de esa población?
En principio sí. Simplemente tendríamos que hacer una encuesta entre
todos los hogares y calcular la media. Sin embargo, seguir ese proceso sería tremendamente laborioso y complicaría bastante el estudio.
Ante situaciones así, se hace más factible seleccionar una muestra estadística.
Por ejemplo, 500 personas. Y sobre dicha muestra, calcular la media.
Aunque seguiríamos sin saber el verdadero valor poblacional, podríamos
suponer que este se va a situar cerca del valor muestral. A esa media le
sumamos el margen de error y tenemos un valor del intervalo de
confianza. Por otro lado, le restamos a la media ese margen de error y
tendremos otro valor. Entre esos dos valores estará la media
poblacional.
En conclusión, el intervalo de confianza no sirve para dar una
estimación puntual del parámetro poblacional, si nos va a servir para
hacernos una idea aproximada de cuál podría ser el verdadero de este.
Nos permite acotar entre dos valores en dónde se encontrará la media de
la población.
Factores de los que depende un intervalo de confianza
El cálculo de un intervalo de confianza depende principalmente de los siguientes factores:
Tamaño de la muestra seleccionada: Dependiendo
de la cantidad de datos que se hayan utilizado para calcular el valor
muestral, este se acercará más o menos al verdadero parámetro
poblacional.
Nivel de confianza: Nos va a informar en qué porcentaje de casos nuestra estimación acierta. Los niveles habituales son el 95% y el 99%.
Margen de error de nuestra estimación:
Este se denomina como alfa y nos informa de la probabilidad que existe
de que el valor poblacional esté fuera de nuestro intervalo.
Lo estimado en la muestra (media, varianza, diferencia de medias…): De esto va a depender el estadístico pivote para el cálculo del intervalo.
Ejemplo de intervalo de confianza para la media, asumiendo normalidad y conocida la desviación típica
El estadístico pivote utilizado para el cálculo sería el siguiente:
El intervalo resultante sería el siguiente:
Vemos como en el intervalo a la izquierda y derecha de la desigualdad
tenemos la cota inferior y superior respectivamente. Por tanto la
expresión nos dice, que la probabilidad de que la media poblacional se
sitúe entre esos valores es de 1-alfa (nivel de confianza).
Veamos mejor lo anterior con un ejercicio resuelto a modo de ejemplo.
Se desea estimar la media del tiempo que un corredor emplea para
completar una maratón. Para ello se han cronometrado 10 maratones y se
ha obtenido una media de 4 horas con una desviación típica de 33 minutos
(0,55 horas). Se desea obtener un intervalo al 95% de confianza.
Para obtener el intervalo, no tendríamos más que sustituir los datos en la fórmula del intervalo.
El intervalo de confianza, sería la parte de la distribución que
queda sombreada en azul. Los 2 valores acotados por este serían los
correspondientes a las 2 líneas de color rojo. La linea central que
parte la distribución en 2 sería el verdadero valor poblacional.
Es importante resaltar que en este caso, dado que la función de
densidad de la distribución N(0,1) nos da la probabilidad acumulada
(desde la izquierda hasta el valor crítico), tenemos que encontrar el
valor que nos deja a la izquierda 0,975% (este es 1,96).
Tamaño de muestra determinado para obtener significancia estadística con una probabilidad determinada
Supongamos que nuestro objetivo es demostrar que más de la mitad de la población
apoya la pena de muerte, esto es p>0.5
, nuevamente tenemos la hipótesis que el
verdadero valor es p=0.6.
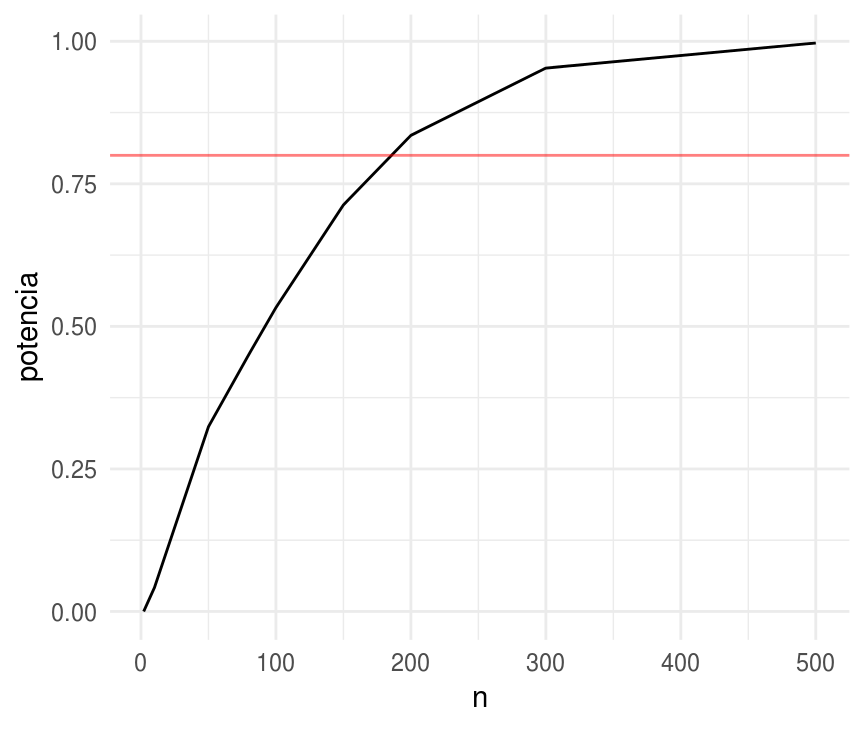
Una prueba de potencia típica tiene un poder de 80
%, es decir nos gustaría
seleccionar n tal que el 80% de los intervalos construidos con 95% de
confianza no incluyan 0.5. Para encontrar la n tal que el 80% de las
estimaciones estén al menos, 1.96 errores estándar por encima de 0.5
necesitamos que: 0.5+1.96se≥0.6−0.84se
Sustituyendo se=0.5/√(n)
obtenemos n=196
Y simulando sería
Veamos un ejemplo más interesante, en donde usamos simulación de un modelo
probabilístico. Tenemos medidas del sistema inmune
(porcentaje de CD4 transformado con raíz cuadrada) de niños VIH positivos a lo
largo de un periodo de 2
años. Las series de tiempo se ajustan de manera
razonable con un modelo de intercepto y pendiente variable: yi∼N(αj[i]+βj[i]ti,σ2y)
donde i
indexa las mediciones tomadas al tiempo i en el individuo j[i].
# preparación de los datoslibrary(lme4)allvar<-read.csv("data/allvar.csv")cd4<-allvar%>%filter(treatmnt==1, !is.na(CD4PCT), baseage>1, baseage<5)%>%mutate(y=sqrt(CD4PCT),
person=newpid,
time=visage-baseage)
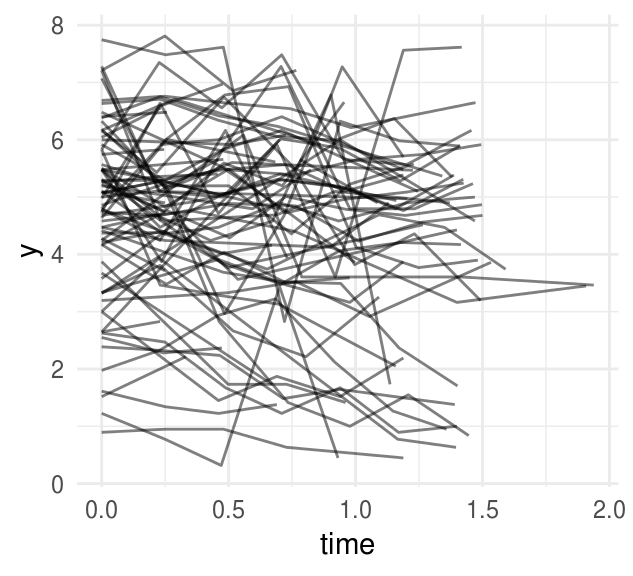
La siguiente gráfica muestra las mediciones para cada individuo, podemos ver que
las series de tiempo son ruidosas.
Veamos un ajuste usando la función lmer() del paquete lme4.
fit_cd4<-lmer(formula=y~time+(1+time|person), cd4)fit_cd4#> Linear mixed model fit by REML ['lmerMod']#> Formula: y ~ time + (1 + time | person)#> Data: cd4#> REML criterion at convergence: 1096#> Random effects:#> Groups Name Std.Dev. Corr#> person (Intercept) 1.329 #> time 0.680 0.15#> Residual 0.748 #> Number of obs: 369, groups: person, 83#> Fixed Effects:#> (Intercept) time #> 4.846 -0.468
Notamos que las tendencias sobre el tiempo β
tienen un promedio estimado
en −0.5 con desviación estándar de 0.7, es decir, estimamos que la mayoría
de los niños tienen niveles de CD4 decrecientes, pero no todos.
Usaremos estos resultados para hacer calculos de potencia para una nueva prueba
que busca medir el efecto del consumo de zinc en la dieta. Quisiéramos que el
estudio fuera suficientemente grande para que con probabilidad de al menos 80
%
la media del efecto del tratamiento sea significativo con un nivel de confianza
del 95%.
Necesitamos hacer supuestos del efecto del tratamiento y del resto de los
parámetros que caracterizan el estudio. El análisis de arriba muestra que en los
niños VIH positivos que no recibieron zinc los niveles de CD4 caían en promedio
0.5
al año. Suponemos que con el zinc reduciremos la caída a cero. yi∼N(αj[i]+βj[i]ti,σ2y)
(αjβj)∼N[(γα0γβ0+γβ1zj),(σ2αρσασβρσασβσ2β)]
donde zj={1si el j-ésimo niño recibió trataiento0e.o.c
El tratamiento zj
afecta la pendiente βj más no el intercepto αj
pues el tratamiento no puede afectar en el tiempo cero. Usando los datos del ajuste
de arriba tenemos que para el grupo control la pendiente será: γβ0=−0.5
y el efecto del tratamiento γβ1=0.5,
el resto de los parámetros los especificamos de acuerdo al ajuste de arriba.
Por simplicidad fijaremos la correlación ρ en cero.
El siguiente paso es determinar el diseño del modelo, suponemos que dividiremos
a J
niños VIH positivos en dos grupos del mismo tamaño, J/2 de ellos
recibirán el cuidado usual y J/2 recibirán suplementos de zinc. Más aún
suponemos que se medirá el porcentaje de CD4 cada 2 meses durante un año.
Usaremos simulación para determinar el tamaño de muestra J
que se requiere
para tener una potencia de 80% si el verdadero efecto es 0.5, ¿cuál es el
modelo gráfico asociado?
# cd4_sim simula del modelo con los supuestos que fijamos arriba# podemos variar los valores de los parámetros para cambiar el escenariocd4_sim<-function(J, K, mu.a.true=4.8, g.0.true=-0.5, g.1.true=0.5,
sigma.y.true=0.7, sigma.a.true=1.3, sigma.b.true=0.7){time<-rep(seq(0, 1, length=K), J)# K mediciones en el añoperson<-rep(1:J, each=K)# idstreatment<-sample(rep(0:1, J/2))treatment1<-treatment[person]# parámetros a nivel personaa.true<-rnorm(J, mu.a.true, sigma.a.true)b.true<-rnorm(J, g.0.true+g.1.true*treatment, sigma.b.true)y<-rnorm(J*K, a.true[person]+b.true[person]*time, sigma.y.true)return(data.frame(y, time, person, treatment1))}# calcular si el parámetro es significativo para una generación de simulacióncd4_signif<-function(J, K){fake<-cd4_sim(J, K)lme_power<-lmer(y~time+time:treatment1+(1+time|person), data=fake)theta_hat<-fixef(lme_power)["time:treatment1"]theta_se<-summary(lme_power)$coefficients["time:treatment1", "Std. Error"]theta_hat-1.96*theta_se>0}# repetir la simulación de cd4 n_sims veces y calcular el porcntaje de las# muestras en que es significativo el parámetro (el poder)cd4_power<-function(n_sims, J, K){rerun(n_sims, cd4_signif(J, K=7))%>%flatten_dbl()%>%mean()}
Estadística Descriptiva Examinaremos los datos en forma descriptiva con el fin de: • Organizar la información
• Sintetizar la información
• Ver sus características más relevantes
• Presentar la información
Factores necesarios para un buen análisis estadístico: • Diseño del Experimento o Investigación
• Calidad de los Datos
Definimos: Población: conjunto total de los sujetos o unidades de análisis de interés en el estudio Muestra: cualquier subconjunto de sujetos o unidades de análisis de la población en estudio.
Organizaremos la información que proveen los datos De manera de detectar algún patrón de comportamiento, así como también apartamientos importantes al modelo subyacente.
Asimismo, definimos:
- UNIDAD DE ANÁLISIS O DE OBSERVACIÓN: al objeto bajo estudio. Puede ser una persona, una familia, un país, una institución o en general, cualquier objeto. - VARIABLE: a cualquier característica de la unidad de observación que interese registrar y que en el momento de ser registrada puede ser transformada en un número.
- VALOR de una variable, DATO u OBSERVACIÓN o MEDICIÓN: al número que describe a la característica de interés en una unidad de observación particular.
- CASO o REGISTRO: al conjunto de mediciones realizadas sobre una unidad de observación.
4.6.
Simulación de los comporta-mientos aleatorios del proyecto y su verificación.
La ejecución de un proyecto de simulación requiere el seguimiento de un proceso secuencial en tres fases: 1. Evaluación y diseño. Esta primera fase supone actividades tales como: 1.1 Identificar dentro de la organización al responsable-promotor del proceso de simulación, lo que permite conseguir el compromiso de la gerencia. 1.2 Determinar las necesidades de simulación. Para ello habrá que determinar cuestiones tales como las características del proceso a modelizar (los procesos con altas tasas de transacciones pero de flujo directo tienen necesidades distintas que los procesos de baja tasa con flujos múltiples y complejos), si la modelización supondrá reingeniería de proceso, con qué frecuencia se realizarán las simulaciones, quienes serán los usuarios finales, etc. 1.3 Estimar los recursos necesarios, mediante la elaboración de un plan financiero y un presupuesto en el que se estimen tanto los costes de puesta en marcha de la tecnología de simulación, como los de su aplicación. 1.4 Evaluar y seleccionar las tecnologías de simulación disponibles. Ello permite evaluar el coste y el tiempo necesario para realizar el proyecto. Cuando se inicia un estudio de simulación, puesto que estamos en el momento de arranque de la investigación, una primera aproximación para construir un modelo consiste en la utilización de funciones "lo mas sencillas posibles", por ejemplo, polinomios de primer o segundo grado, [Houck, E. C, Cooley, B. J.; 1983]. Un ejemplo de función polinómica de primer grado utilizada para estos estudios iniciales podría ser: k Y = β0 + Σ βi Xi + ε i Y un ejemplo de función polinómica de segundo grado podría ser: k k k k Y = β0 + Σ βi Xi + Σ βii Xi 2 + Σ Σ βij Xi Xj + ε i=l i=l i=l j=l (i < j) Siendo "Y" la respuesta estimada y “ε” el factor aleatorio. A medida que se va rodando el modelo se va llegando a la región de respuesta óptima. En los experimentos iniciales, el modelo de primer grado puede dar una estimación bastante aproximada de la respuesta óptima y será útil para identificar las siguientes regiones de exploración. Se utilizan las funciones de primer grado hasta que el modelo es incapaz de explicar lógicamente la respuesta obtenida, se adivina entonces la presencia de una curva y se pasa a una función de un grado superior para la exploración de las regiones posteriores. En este caso sería una función de segundo grado fácilmente tratable matemáticamente. Una vez que la región óptima está localizada, el modelo de simulación servirá como herramienta para estimar los coeficientes óptimos para las variables clave y realizar un análisis de sensibilidad del sistema. Cada empresa tiene una serie de variables independientes y otras dependientes relacionadas entre sí a través de sendas relaciones causa efecto. Los 3 métodos de simulación mas comunes son: 1.4.1 Métodos analíticos. Están basados en técnicas asociadas a la teoría de colas, consistiendo esencialmente en nódulos ensamblados entre sí en una red multinivel. La simulación analítica pone de manifiesto múltiples aspectos ligados a la complejidad dinámica de los procesos en los que varios agentes compiten por un mismo recurso, así como la variabilidad asociada a procesos de entrada-salida. Los modelos analíticos proporcionan estimaciones sobre hechos agregados estables con más precisión que el análisis proporcionado por series de datos. 1.4.2 Métodos continuos. En esta aproximación, el comportamiento de los procesos se simula utilizando ecuaciones diferenciales que reflejan la variación en el tiempo de cada variable de estado. Una variable de estado podría ser la tasa de llegada de órdenes o la tasa de procesamiento de un recurso. Estos modelos son apropiados para modelizar procesos de gran volumen o producciones continuas. Evidentemente, se ha de suponer que las variables de estado varían de forma continua y diferenciable en el tiempo (generalmente, las ecuaciones diferenciales se utilizan cuando el tamaño del paso del tiempo es pequeño). Se trata de determinar los valores corrientes de las variables de estado hasta el momento en el cual se alcanza un umbral que pone en marcha ciertas acciones. Las ecuaciones diferenciales pueden tener en cuenta comportamientos de tipo estocástico, y los modelos correspondientes han de ser capaces de modelizar tanto los fenómenos de transición como los estados de equilibrio. Dos grandes retos para los modelizadores que utilizan estas técnicas son el desarrollo de ecuaciones que describan los comportamientos aleatorios dependientes del tiempo, así como evaluar los resultados obtenidos mediante la resolución analítica o numérica de dichas ecuaciones. 1.4.3 Métodos discretos. En este tipo de simulación, las variables de estado del modelo evolucionan sobre un conjunto discreto de puntos, quizás aleatorio, del eje de tiempos. En estos modelos, los flujos temporales entre los puntos del mencionado conjunto compiten unos con otros por el uso de los recursos escasos. Estos modelos permiten simular comportamientos aleatorios introduciendo distribuciones de probabilidad discretas.; por ello, los resultados obtenidos por estos modelos discretos son asimismo aleatorios, con lo que tan solo pueden ser tomados como una estimación del comportamiento real, siendo necesario múltiples aproximaciones y/o replicaciones para que el resultado obtenido, en términos medios, se aproxime al real. Dado que se trata de modelos discretos, se puede recurrir a la modelización mediante ecuaciones en diferencias finitas (si los puntos del eje de tiempos son aleatorios, es seguro que no estarán igualmente espaciados, entonces resulta mas complejo la utilización de técnicas asociadas a ecuaciones en diferencias finitas). En un proceso de simulación de tipo discreto, se introducen en el modelo entidades que representan productos y servicios, y que al competir por los recursos que permiten llevar a cabo las actividades, los consumen. Es la técnica de simulación mas natural para modelizar y analizar procesos. 1.4.4 Todos orientados a objetos. Esta técnica de modelización contempla a procesos, productos, servicios y recursos como si de objetos se tratara. Cada objeto está formado por una combinación de información (atributos) y procedimientos (métodos); ambos se combinan para crear un “ejemplar” del objeto en cuestión. Por ejemplo, un objeto denominado "cliente" puede tener como atributos edad, capacidad de endeudamiento y nivel de educación. En un proceso convencional de solicitud de hipoteca, todos los formularios de préstamo recorren un mismo proceso basado en ciertas pautas, pero usando un modelo orientado a objetos, se puede definir una información única para un cliente específico y los procedimientos exclusivos a utilizar con su formulario de solicitud de préstamo. Los métodos orientados a objetos reducen drásticamente los tiempos de desarrollo de los modelos en el sentido de que no será preciso volver a construirlo desde la base, se puede utilizar una plantilla versátil y reutilizarla. El propósito de la simulación y modelización orientada a objetos es facilitar la posibilidad de crear complejos submodelos que maximicen su ciclo de vida y permitan su integración en otros modelos. Este método permite incorporar las técnicas anteriormente tratadas, tanto analíticas como continuas y discretas, ya que para modelizar los flujos intermedios entre los objetos; se puede recurrir a submodelos que utilicen dichas herramientas. 1.5. Analizar las relaciones entre herramientas y métodos de simulación con el fin de obtener sinergias. El proceso de simulación está estrechamente relacionado con ciertas herramientas y métodos tales como cartografía de procesos mediante flujogramas, sistemas de coste basados en las actividades, así como el diseño de experimentos. 1.6. Evaluar y seleccionar el software de simulación. Este paso es de vital importancia. Dedicamos el apartado siguiente de nuestro trabajo a tratar de este tema con más detalle. 1.7. Recibir la formación pertinente y gestionar el proyecto piloto. Gestionar el proyecto piloto supone acciones tales como análisis y captura de datos de entrada, construcción del modelo piloto, diseño y realización de pruebas y análisis de los datos de salida. Los procesos más susceptibles de modelización son aquellos para los que es posible la representación mediante flujogramas, los que van a ser sujetos a reingeniería, aquellos a los que ha sido aplicado el benchmarking, los que tienen gran impacto en la cadena de valor, los que se les han adaptado nuevas aplicaciones de software, los que presentan algún problema de costes, planificación o ciclo temporal, y los que han sido desarrollados usando un análisis basado en las actividades. 2. Ejecución. Una vez que el proyecto piloto ha tenido éxito, confirmando la conveniencia de la simulación, la fase de ejecución puede dar comienzo. Esta fase comprende las siguientes etapas: 2.1. Diseño del proyecto de simulación. Para completar esta etapa es preciso realizar tres tares: 2.1.1. Definir los objetivos que se desean alcanzar con el modelo de simulación. Los más comunes suelen ser análisis del funcionamiento de un proceso (si actúa de forma correcta bajo un determinado conjunto de circunstancias en medidas significativas tales como utilización de recursos, rendimiento, tiempos de espera, etc.), análisis de la capacidad del proceso (cuál es el máximo de capacidad de procesamiento), o saber si el proceso es capaz de hacer frente a requerimientos específicos, un análisis de sensibilidad sobre aquellas variables de decisión esenciales, o bien un análisis de optimización sobre un conjunto de valores de variables de decisión. 2.1.2. Definir las restricciones. Tan importante como definir los objetivos es identificar las restricciones que afectan al proyecto de simulación. Una restricción importante es el tiempo; no tiene sentido proyectar una simulación para resolver un problema si el tiempo de ejecución se extiende mas allá del plazo posible para su resolución. 2.1.3. Definir el campo de actuación del modelo. Ello incluye aspectos tales como la extensión del modelo, nivel de detalle, grado de precisión, tipo de pruebas a realizar y contenido y formato de presentación de los resultados. Definir las fronteras del modelo supone encuadrarlo dentro de unos límites superiores e inferiores, así como delimitar su principio y final. 2.2. Captura y análisis de datos. Previamente es preciso hacer una clasificación de datos distinguiendo entre variables que dependen del tiempo, las que dependen de los recursos y las que dependen de determinadas condiciones, así como diferenciar las variables de entrada de las variables de respuesta, y sobre todo, determinar los requerimientos de datos y conocer las fuentes de los mismos. Resulta de utilidad visualizar y documentar los datos y flujos del proceso mediante un flujograma (como mencionábamos en el apartado anterior). 2.3. Construcción del modelo. Una de las ventajas de la simulación se encuentra en que los modelos no han de incluir todos sus detalles para poder ponerlos en funcionamiento; ello permite que en su construcción se vayan realizando refinamientos progresivos hasta conseguir el formato definitivo. Es mejor comenzar con un modelo simple e ir añadiendo complejidad de forma paulatina. Conviene tener presente que con la tecnología de simulación orientada a objetos, que hace posible la reutilización, junto con la disponibilidad de herramientas de simulación adaptables y la creciente integración de métodos de representación de procesos tales como los flujogramas, es posible utilizar modelos de simulación de forma reiterada sin necesidad de construirlos de nuevo desde el principio. Por ejemplo, la simulación puede ser utilizada para la toma de decisiones estratégicas tales como determinar la factibilidad de diferentes alternativas de niveles de producción o estrategias alternativas sobre niveles de existencias. Modelizada una configuración, su algoritmo puede ser utilizado de nuevo a nivel operacional como base para desarrollar otro sistema de control para la toma de decisiones lógicas en cualquier otro punto de gestión del proceso. 2.4. Verificación del modelo. Realización de análisis, pruebas y presentación de resultados. 3. Medida de logros y mejora continua. Esta fase comprende acciones tales como revisión de metas y principios, debates, establecimiento de informes y procedimientos de retroalimentación y ejecución de procesos de mejora continua.
Qué son los cuadrados medios? Los cuadrados medios representan una estimación de la varianza de la población. Se calculan dividiendo la suma correspondiente de los cuadrados entre los grados de libertad. Regresión En regresión, los cuadrados medios se utilizan para determinar si los términos de un modelo son significativos. El cuadrado medio del término se obtiene dividiendo la suma de los cuadrados del término entre los grados de libertad. El cuadrado medio del error (MSE) se obtiene dividiendo la suma de los cuadrados del error residual entre los grados de libertad. El MSE es la varianza (s 2 ) en torno a la línea de regresión ajustada. Al dividir el MS (término) entre el MSE, se obtiene F, que sigue la distribución F con grados de libertad para el término y grados de libertad para el error. ANOVA En ANOVA, los cuadrados medios se utilizan para determinar si los factores (tratamientos) son significativos. El cuadrado medio del tratamiento se obtiene divid...
E n t i d a d Es toda colectividad que puede considerarse como una unidad, refiriendose al estado donde vives o algun centro commercial, donde f orman parte de un sistema quebpermiten las entradas y salidas, administrandose en factor al tiempo para ofrecer la mejor calidad y servicio. https://youtu.be/Y5MwA3k-LLU
4.1. Lista de estimadores a obtener de la simulación Definiremos algunas propiedades de los estimadores. 1) Parámetro. Verdadero valor de una característica de interés, denominado por θ, que Raramente es conocido. 2) Estimativa. Valor numérico obtenido por el estimador, denominado de θ̂ en una muestra. 3) Viés y no viés. Un estimador es no in-sesgado si: E(θ̂) = θ, donde el viés es dado por: vies (θ̂) = E(θ ˆ θ) = E(θ̂) − θ Cuadrado medio del error (ECM). Es dado por: ECM (θ̂) = E(θ̂ − θ)2 = V (θ̂) + (vies) 1) Un estimador es consistente si: plim(θ̂) = θ ; y lim −→ ∞ECM (θ̂) = 0 2) Las leyes de los grandes números explican por qué́ el promedio o media de una muestra al azar de una población de gran tamaño tenderá a estar cerca de la media de la población completa. 4.1.1. Instrumentos de medición El análisis de la literatura existente arroja un resultado de 17 instrumentos de medida de las actitudes y la ansiedad hacia la est...
 • Reducir la elaboración de prototipos
• Reducir la elaboración de prototipos  Siendo:n = Tamaño de la muestra que deseamos calcular (número de observaciones)
Siendo:n = Tamaño de la muestra que deseamos calcular (número de observaciones)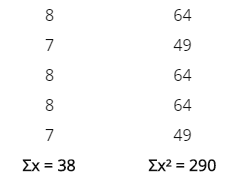 n’ = 5Sustituyendo estos valores en la fórmula anterior tendremos el valor de n:Dado que el número de observaciones preliminares (5) es inferior al requerido (7), debe aumentarse el tamaño de las observaciones preliminares, luego recalcular n. Puede ser que en recálculo se determine que la cantidad de 7 observaciones sean suficientes.
n’ = 5Sustituyendo estos valores en la fórmula anterior tendremos el valor de n:Dado que el número de observaciones preliminares (5) es inferior al requerido (7), debe aumentarse el tamaño de las observaciones preliminares, luego recalcular n. Puede ser que en recálculo se determine que la cantidad de 7 observaciones sean suficientes.
 Siendo:
Siendo: 5. Buscar ese cociente en la siguiente tabla, en la columna (R/X), se ubica el valor correspondiente al número de muestras realizadas (5 o 10) y ahí se encuentra el número de observaciones a realizar para obtener un nivel de confianza del 95% y un nivel de precisión de ± 5%.
5. Buscar ese cociente en la siguiente tabla, en la columna (R/X), se ubica el valor correspondiente al número de muestras realizadas (5 o 10) y ahí se encuentra el número de observaciones a realizar para obtener un nivel de confianza del 95% y un nivel de precisión de ± 5%.

 Ahora calculamos el cociente entre el rango y la media:
Ahora calculamos el cociente entre el rango y la media: Ahora buscamos ese cociente en la tabla y buscamos su intersección con la columna de 10 observaciones:
Ahora buscamos ese cociente en la tabla y buscamos su intersección con la columna de 10 observaciones: Tenemos entonces que el número de observaciones a realizar para tener un nivel deconfianza del 95% según el método tradicional es: 11Al adicionar los 5 tiempos y utilizar el método estadístico tenemos un número de observaciones igual a: 12.8 aproximadamente 13.Por lo cual podemos concluir que ambos métodos arrojan resultados muy parecidos y que la elección del método se deja a criterio del especialista.https://www.ingenieriaindustrialonline.com/estudio-de-tiempos/calculo-del-numero-de-observaciones/
Tenemos entonces que el número de observaciones a realizar para tener un nivel deconfianza del 95% según el método tradicional es: 11Al adicionar los 5 tiempos y utilizar el método estadístico tenemos un número de observaciones igual a: 12.8 aproximadamente 13.Por lo cual podemos concluir que ambos métodos arrojan resultados muy parecidos y que la elección del método se deja a criterio del especialista.https://www.ingenieriaindustrialonline.com/estudio-de-tiempos/calculo-del-numero-de-observaciones/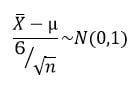 El intervalo resultante sería el siguiente:
El intervalo resultante sería el siguiente:
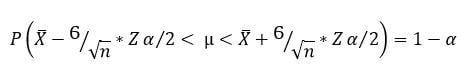

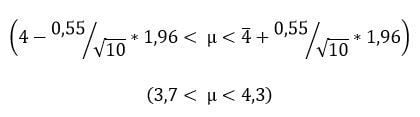 El intervalo de confianza, sería la parte de la distribución que queda sombreada en azul. Los 2 valores acotados por este serían los correspondientes a las 2 líneas de color rojo. La linea central que parte la distribución en 2 sería el verdadero valor poblacional.
El intervalo de confianza, sería la parte de la distribución que queda sombreada en azul. Los 2 valores acotados por este serían los correspondientes a las 2 líneas de color rojo. La linea central que parte la distribución en 2 sería el verdadero valor poblacional.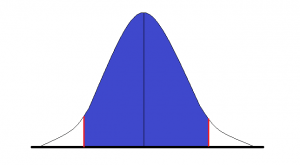

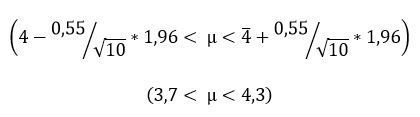

Comentarios
Publicar un comentario